# import de données
library(readr)
library(tools)
# manipulation de données
library(dplyr)
library(tidyr)
# travail sur les dates
library(lubridate)
# travail sur les chaines de caractères
library(stringr)
# visualisation
library(ggplot2)
#library(ggspatial)
# données spatiales
library(sf)Introduction aux données d’IdFM
Les données
Nous allons utiliser les données en open data mises à disposition par IdFM, l’autorité organisatrice des transports en île de france. Les différents jeux de données sont disponnibles sur le portail open data d’IdFM:
https://data.iledefrance-mobilites.fr/pages/home/
Nous allons en particulier nous intéresser aux données historiques sur les validations du réseau ferré francilien. Ce notebook est là pour vous aider à prendre en main ces données et discuter de certaines difficultés liées à leur traitement et nettoyage.
Quelques librairies utiles
Téléchargement et lecture des données
Les schémas des jeux de données des validations historiques diffèrent subtilement entre 2022 et les années précédentes, et sont les suivant :
schema= cols(
JOUR = col_date(format="%d/%m/%Y"),
CODE_STIF_TRNS = col_character(),
CODE_STIF_RES = col_character(),
CODE_STIF_ARRET = col_character(),
LIBELLE_ARRET = col_character(),
ID_REFA_LDA = col_character(),
CATEGORIE_TITRE = col_character(),
NB_VALD = col_character()
)
schema2022= cols(
JOUR = col_date(format="%Y-%m-%d"),
CODE_STIF_TRNS = col_character(),
CODE_STIF_RES = col_character(),
CODE_STIF_ARRET = col_character(),
LIBELLE_ARRET = col_character(),
ID_REFA_LDA = col_character(),
CATEGORIE_TITRE = col_character(),
NB_VALD = col_double()
)Nous avons donc pour chaque journées, pour chaque lieux d’arrêt et chaque catégories de titre, un nombre de validation. La documentation complète sur les données et la définition des variables est disponnible a cette adresse : https://eu.ftp.opendatasoft.com/stif/Validations/Donnees_de_validation.pdf. Les variables CODE_STIF_TRNS,RES,ARRET correspondent respectivement à une codification des transporteurs (ratp,sncf,optiles,…), des réseaux (métros,rer,train de banlieu,…) et des arrêts. La variable ID_REF_LDA correspond à un code de “zone d’arrêts”. (i.e Zone monomodale basé avant tout sur une cohérence commerciale (et géographique) : connue du public sous la même appellation commerciale.)
Avant 2022, lorsqu’un comptage est inférieur à 5, il est remplacé par la chaine de caractères “moins de 5”, à partir de 2022 il est simplement remplacé par la valeur 5. Les codes suivants permettent de télécharger les données et de les concaténer. Les codes effectuant les téléchargement ont été commentés.
url="https://data.iledefrance-mobilites.fr/api/explore/v2.1/catalog/datasets/histo-validations-reseau-ferre/exports/csv?lang=fr&timezone=Europe%2FBerlin&use_labels=true&csv_separator=%3B"
#download.file(url,"./data-raw/histo-validations-reseau-ferre.csv")
files = read_delim("./data-raw/histo-validations-reseau-ferre.csv",delim=";")
colnames(files)=c("year","url")
# ## DECOMENTER pour télécharger les données brutes
# lapply(1:nrow(files), \(i){
# download.file(files$url[i],paste0("./data-raw/",files$year[i],".zip"), mode = "wb")
# unzip(paste0("./data-raw/",files$year[i],".zip"),exdir = "./data-raw")
# })
directories=list.dirs("./data-raw")
data.list=lapply(directories[-1],\(dir){
files=list.files(dir,full.names = TRUE)
cf = files[grepl("NB_FER",files)]
if(file_ext(cf[1])=="csv"){
cdf.list = lapply(cf,\(f){read_delim(f,delim=";",col_types = schema)})
}else{
cdf.list = lapply(cf,\(f){read_delim(f,delim="\t",col_types = schema)})
}
do.call(dplyr::bind_rows,cdf.list)
})
#url2022="https://data.iledefrance-mobilites.fr/api/explore/v2.1/catalog/datasets/validations-reseau-ferre-nombre-validations-par-jour-1er-semestre/exports/csv?lang=fr&timezone=Europe%2FBerlin&use_labels=true&csv_separator=%3B"
#download.file(url2022,"./data-raw/2022_S1_NB_FER.csv")
data2022=read_delim("./data-raw/2022_S1_NB_FER.csv",delim=";",col_types=schema2022)
data.val = do.call(dplyr::bind_rows,data.list) |>
mutate(NB_VALD=ifelse(NB_VALD=="Moins de 5",5,NB_VALD),NB_VALD=as.numeric(NB_VALD))|>
bind_rows(data2022)A ce point d’avancement, nous disposons de données brutes homogénéisées et concaténées dans une unique data.frame.
Choix d’une échelle d’aggregation et nettoyage
Pour travailler, nous avons fait le choix de nous placer à l’échelle de la zone d’arrêt, du jour et de ne considérer pour le moment que le volume total de validation. Nous commençons donc par faire une aggregation des données à cette échelle. Mais avant cela nous allons tout de même vérifier quelques éléments sur les données:
table(data.val$ID_REFA_LDA) |> head()
? 0 411281 411284 412687 412697
9781 11886 5126 5185 18064 18523 sum(is.na(data.val$ID_REFA_LDA))[1] 5410data.val |> filter(is.na(ID_REFA_LDA)) |> select(2:5) |> distinct()# A tibble: 1 × 4
CODE_STIF_TRNS CODE_STIF_RES CODE_STIF_ARRET LIBELLE_ARRET
<chr> <chr> <chr> <chr>
1 100 110 682 PORTE DAUPHINEsum(is.na(data.val$NB_VALD))[1] 0sum(is.na(data.val$JOUR))[1] 0La variable LDA présente 3 modalités problématiques “?”,“0” et “NA”. Les deux premières correspondent à un problème de localisation et seront filtrées, la dernière correspond toujours aux données de la station Porte Dauphine et peut donc être corrigée. Les deux autres variables ne présentent pas de données manquantes ou de valeurs problématiques. Le code suivant va donc agréger les données et corriger les problèmes identifiés.
data.val.cl = data.val |>group_by(JOUR,ID_REFA_LDA) |>
summarise(NB_VALD=sum(NB_VALD),NAME=first(LIBELLE_ARRET)) |>
mutate(year=year(JOUR)) |>
arrange(ID_REFA_LDA,JOUR) |>
ungroup() |>
filter(ID_REFA_LDA!="?" & ID_REFA_LDA!=0) |> # supression des données sans localisation
mutate(ID_REFA_LDA=ifelse(is.na(ID_REFA_LDA),474152,ID_REFA_LDA)) # correction des données de porte dauphineObservons maintenant pour chaque stations la plage temporelle de données recueillie et ne conservons que les stations dont les plages sont différentes de celles attendues (du 1er Janvier 2015 au 30 Juin 2022) :
data.val.cl |>
group_by(ID_REFA_LDA,NAME) |>
summarise(dstart=first(JOUR),dend=last(JOUR)) |>
filter(dstart!="2015-01-01" | dend!="2022-06-30") |>
arrange(NAME,dstart)FALSE # A tibble: 123 × 4
FALSE # Groups: ID_REFA_LDA [103]
FALSE ID_REFA_LDA NAME dstart dend
FALSE <chr> <chr> <date> <date>
FALSE 1 73312 "ALLEE DE LA TOUR RENDEZ-VOUS" 2015-01-01 2017-06-30
FALSE 2 73792 "AUBER" 2015-01-01 2017-06-30
FALSE 3 478926 "AUBER" 2017-07-01 2022-06-30
FALSE 4 73795 "AVENUE FOCH" 2015-01-01 2017-06-30
FALSE 5 71321 "AVENUE FOCH" 2017-07-01 2022-06-30
FALSE 6 71686 "AVRON" 2015-01-01 2017-06-30
FALSE 7 71697 "AVRON" 2017-07-01 2022-06-30
FALSE 8 70441 "BARBARA" 2022-01-05 2022-06-30
FALSE 9 70441 "BARBARA " 2021-12-22 2021-12-23
FALSE 10 71743 "BASTILLE" 2015-01-01 2017-06-30
FALSE # … with 113 more rowsNous pouvons voir qu’un certain nombre de stations ne sont plus observées à partir de 2017 et que d’autres ne sont observées qu’à partir de cette date. En effet, à cette date, le référentiel des zones d’arrêt a été mis a jour et certaines stations ont changées d’identifiant.
# changement d'id
data.idchange=data.val.cl |>
group_by(ID_REFA_LDA,NAME) |>
summarise(tend=last(year),dend=last(JOUR),tstart=first(year),dstart=first(JOUR)) |>
filter(!(tstart==2015 & tend==2022)) |>
arrange(NAME)oldids = data.idchange |> filter(tstart==2015,tend==2017) |> rename(OLD_ID=ID_REFA_LDA)
newids = data.idchange |> filter(tstart==2017,tend==2022) |> rename(NEW_ID=ID_REFA_LDA)cname="AVENUE FOCH"
gg=data.val.cl |> filter(NAME==cname)
ggplot(gg)+geom_line(aes(color=ID_REFA_LDA,x=JOUR,y=NB_VALD),alpha=0.6)+
scale_color_brewer(palette="Set2")+
labs(title=paste("Changement d'identifiant de la station",cname),
x="Date",y="Validation en nombre de passagers")+
theme_bw()+
theme(legend.position="bottom")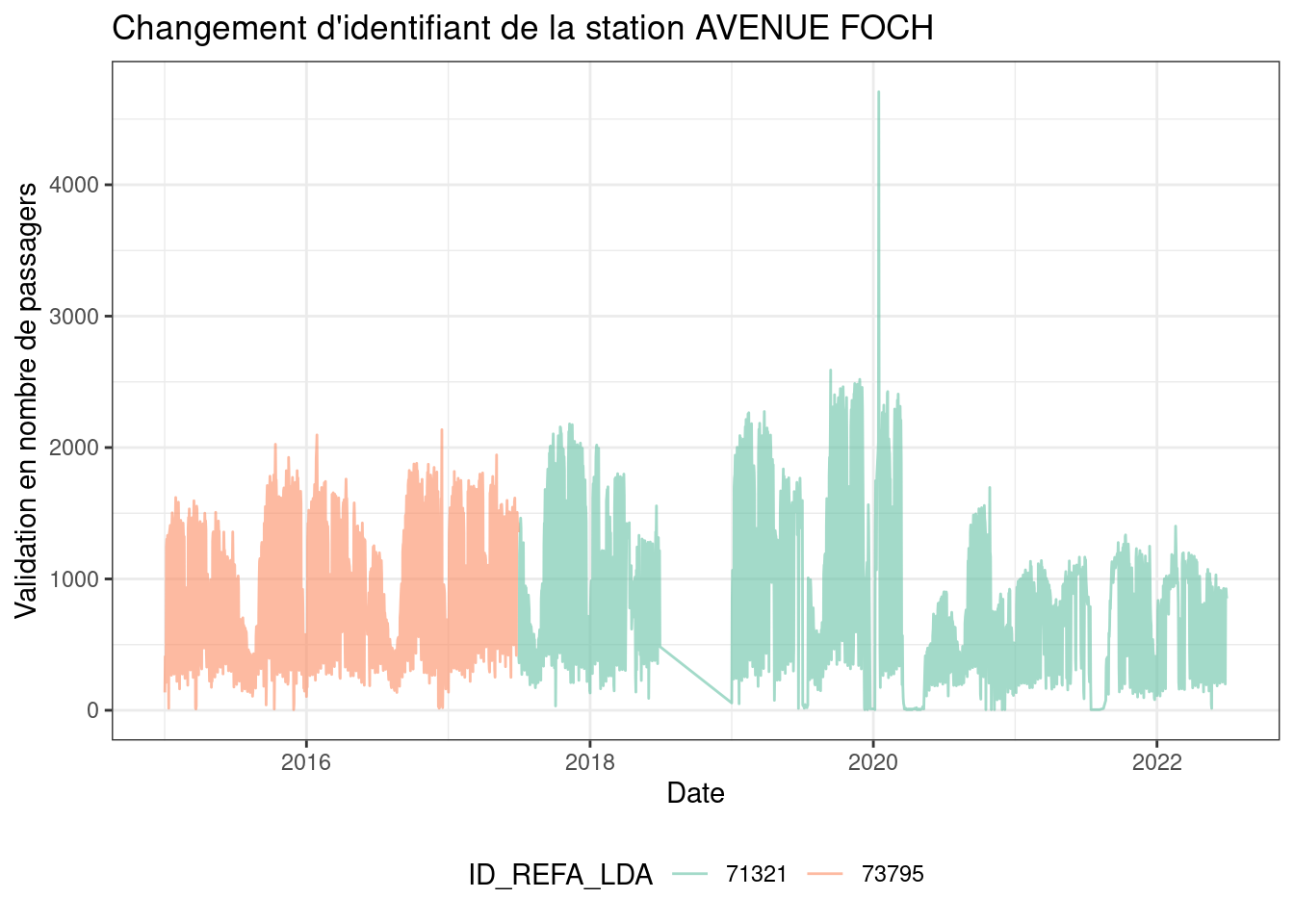
Après verification manuel de la cohérence, nous observons que ces changements correpondent à de simples changements d’identifiant dans un certain nombre de cas mais que certaines stations ont aussi des changement de périmètres en particuliers les stations : “AVRON”, “BUZENVAL”, “HAVRE-CAUMARTIN”, “LE PELETIER”, “LES HALLES”, “CHATELET-LES-HALLES”, “SAINT-LAZARE” qui seront traitée individuellement à cause de changement de périmètre.
cname="SAINT-LAZARE"
gg=data.val.cl |> filter(NAME==cname)
ggplot(gg)+geom_line(aes(color=ID_REFA_LDA,x=JOUR,y=NB_VALD),alpha=0.6)+
scale_color_brewer(palette="Set2")+
labs(title=paste("Changement d'identifiant et de périmètre de la station",cname),
x="Date",y="Validation en nombre de passagers")+
theme_bw()+
theme(legend.position="bottom")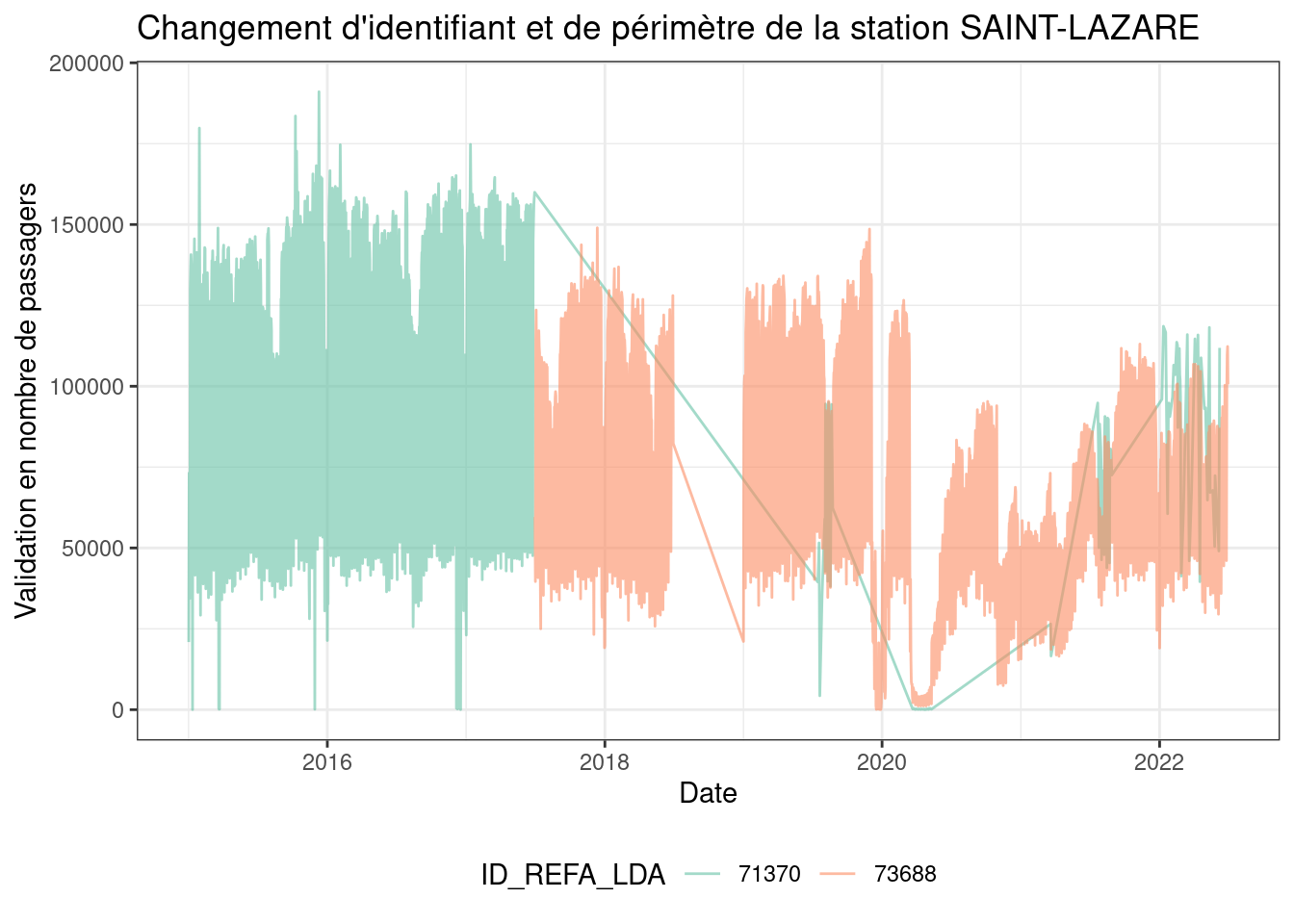
upids = oldids |>
left_join(newids,by=c("NAME"="NAME")) |>
filter(!is.na(NEW_ID)) |>
filter(!NAME %in% c("AVRON", "BUZENVAL", "HAVRE-CAUMARTIN", "LE PELETIER", "LES HALLES", "CHATELET-LES-HALLES", "SAINT-LAZARE")) |>
select(NEW_ID,OLD_ID)
# recodage des ids
data.val.cl2 = data.val.cl |>
left_join(upids,by=c("ID_REFA_LDA"="OLD_ID")) |>
mutate(ID_REFA_LDA=if_else(!is.na(NEW_ID),NEW_ID,ID_REFA_LDA)) |>
select(-NEW_ID)
# verifications
check=duplicated(paste(data.val.cl2$JOUR,data.val.cl2$ID_REFA_LDA))
sum(check)FALSE [1] 0Pour les stations impactées, il faut traiter les stations au cas par cas. Les stations “LE PELLETIER” et “SAINT-LAZARE” ne peuvent être corrigées, chatelet les halles peut être corrigés car avant 2017 la zone comprend chatelet les halles et les halles qui sont désagrégées en deux unités ensuite. Pour uniformiser sur toute la période de temps nous conservons la définition pré 2017.
data.val.cl3 = data.val.cl2 |>
filter(NAME!="LE PELLETIER",NAME!="SAINT-LAZARE") |> # pbr de cohérences dans ces séries
mutate(ID_REFA_LDA= case_when(
NAME=="AVRON" ~ "71697",
NAME=="BUZENVAL"~ "479928",
NAME=="HAVRE-CAUMARTIN" ~ "482368",
TRUE ~ ID_REFA_LDA
)) |>
mutate(NAME=if_else(NAME=="CHATELET-LES HALLES","LES HALLES",NAME),
ID_REFA_LDA=if_else(ID_REFA_LDA=="474141","73794",ID_REFA_LDA)) |>
group_by(JOUR,NAME,ID_REFA_LDA) |>
summarise(NB_VALD=sum(NB_VALD)) |>
ungroup() |>
mutate(LOG_VAL = log(NB_VALD),year=year(JOUR),yd=yday(JOUR),wd=wday(JOUR)) A ce stade des prétraitements, les données sont presque nettoyées. Pour finir, nous uniformisons les libellés et filtrons les series pour ne conserver que celles couvrant toute la période avec un nombre raisonale de validation moyenne par jour et de données manquantes. Ces filtrages sont bien sur dépendant du sujet à traiter et doivent être discutés.
# uniformisation des noms
data.names=data.val.cl3 |>
count(ID_REFA_LDA,NAME) |>
group_by(ID_REFA_LDA) |>
arrange(desc(n)) |>
slice_head(n=1)
data.val.cl4 = data.val.cl3 |>
select(-NAME) |>
left_join(data.names |> select(-n))
# filtrage : observées en 2015 et 2022 ?
id_clean_date = data.val.cl4 |>
group_by(ID_REFA_LDA,NAME) |>
summarise(tstart=first(year),tend=last(year),dend=last(JOUR)) |>
filter(tstart==2015,tend==2022) |>
pull(ID_REFA_LDA)
# statistiques globales par station
st_glob_stats = data.val.cl4 |>
group_by(ID_REFA_LDA,NAME) |>
summarise(M_VALD=mean(NB_VALD),NB_VALD = sum(NB_VALD),NB_J=n()) |>
arrange(desc(NB_VALD))
# filtrage : observée sur au moins 2000 journées avec plus de 500 validations en moyenne par jour ?
id_clean_data= st_glob_stats |>
filter(M_VALD>=500,NB_J>2000) |>
pull(ID_REFA_LDA)
# application du filtrage
data.val.ok = data.val.cl4 |>
filter(ID_REFA_LDA %in% intersect(id_clean_data,id_clean_date))
# statistiques glocables par stations
st_glob_stats = data.val.ok |>
group_by(ID_REFA_LDA,NAME) |>
summarise(M_VALD=mean(NB_VALD),NB_VALD = sum(NB_VALD),NB_J=n()) |>
arrange(desc(NB_VALD))
st_glob_statsFALSE # A tibble: 559 × 5
FALSE # Groups: ID_REFA_LDA [559]
FALSE ID_REFA_LDA NAME M_VALD NB_VALD NB_J
FALSE <chr> <chr> <dbl> <dbl> <int>
FALSE 1 71517 LA DEFENSE-GRANDE ARCHE 117478. 300038131 2554
FALSE 2 73626 GARE DE LYON 79141. 202125000 2554
FALSE 3 73794 LES HALLES 72152. 184203168 2553
FALSE 4 71410 GARE DU NORD 69536. 177593810 2554
FALSE 5 71359 GARE DE L'EST 63454. 162060890 2554
FALSE 6 71139 MONTPARNASSE 50897. 129990494 2554
FALSE 7 71311 REPUBLIQUE 31662. 80739224 2550
FALSE 8 71572 BIBLIOTHEQUE FRANCOIS MITTERRAND 28712. 73274276 2552
FALSE 9 71135 AUSTERLITZ 27581. 70441273 2554
FALSE 10 73620 SAINT-MICHEL 27391. 69874505 2551
FALSE # … with 549 more rowsLes données nettoyées et filtrées sont disponibles directement dans le fichier data.val.ok.RDS.
Quelques premiers graphiques
Afin de mieux connaître nos données, nous allons les visualiser via des graphiques simples afin comprendre les différentes variables du jeu de données et leur dynamique. Les graphiques suivant sont réduit à une station pour réduire le temps de calcul. Ce premier boxplot nous résume les statistiques descriptives du volume de passager par années d’une station.
# Visualisation de l'évolution d'une station durant la période étudier
box = data.val.cl4 |> filter(NAME %in% c("NATION" )) |> mutate(ANNEE = as.character(year))
ggplot(box, aes(ANNEE, y = NB_VALD)) +
geom_boxplot()+
labs(x = 'Date' , y = 'Validation en nombre de passager', title = 'Distribution des volumes passagers par année pour la station de Nation') +
theme_bw()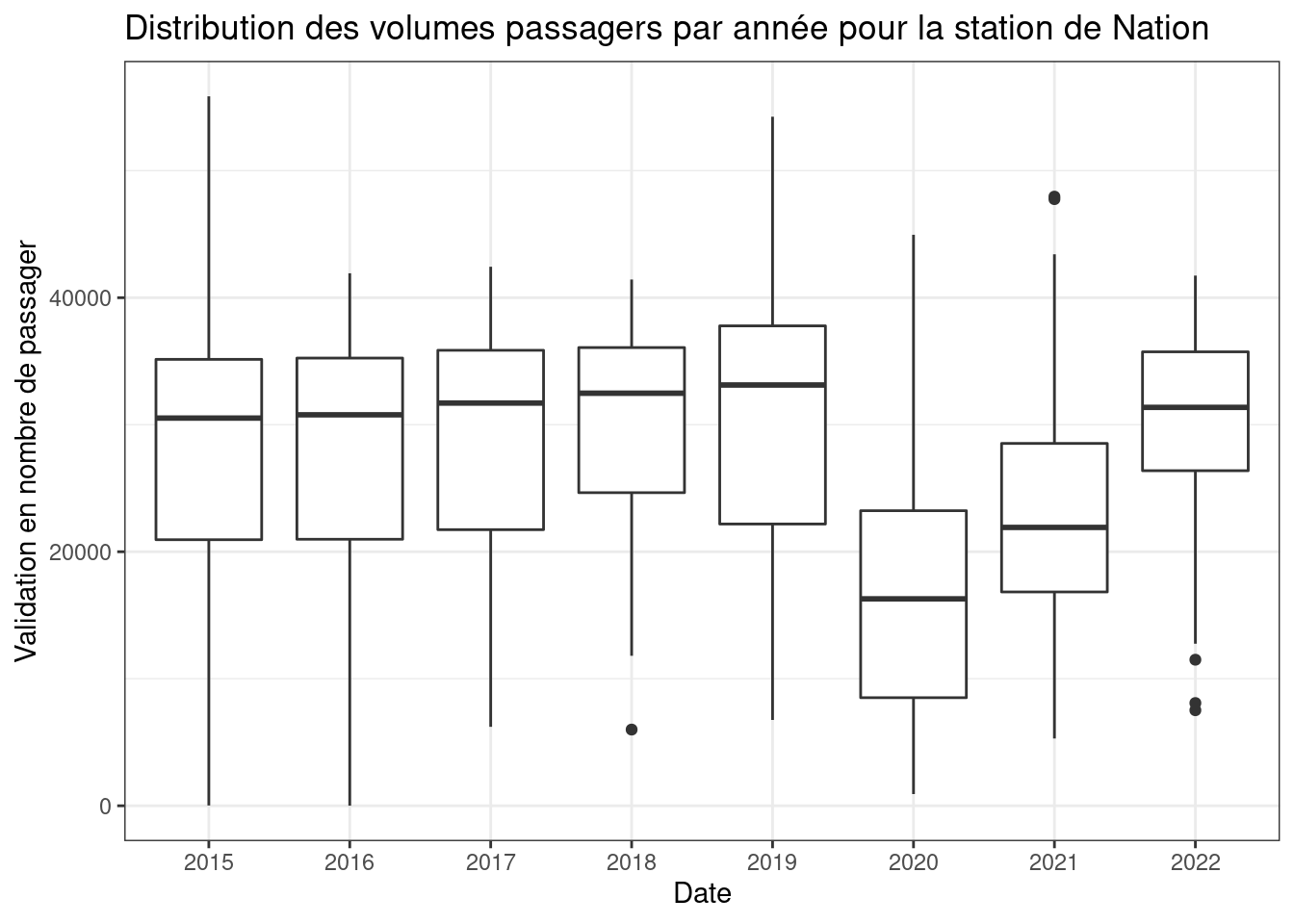
A ce stade on observe que l’années 2020 à connue une forte décrue du volume de passager. En utilisant d’autre fonctions de dessin, nommée “geom_”, nous pouvons mettre en avant chacune des variables en fonction des autres. Le graphique suivant nous montre l’évolution du volume d’une station lors de l’année atypique de 2020 ou l’on peut observer l’impact des confinements sur les TC.
# Visualisation de l'évolution d'une station durant la période étudier
see = data.val.cl4 |> filter(NAME == "NATION") |> filter(year == 2020)
ggplot(see) +
geom_line(aes(JOUR, NB_VALD))+
labs(x = 'Date' , y = 'Validation en nombre de passager', title = 'Validation Par jour pour la Station de Nation en 2020') +
theme_bw()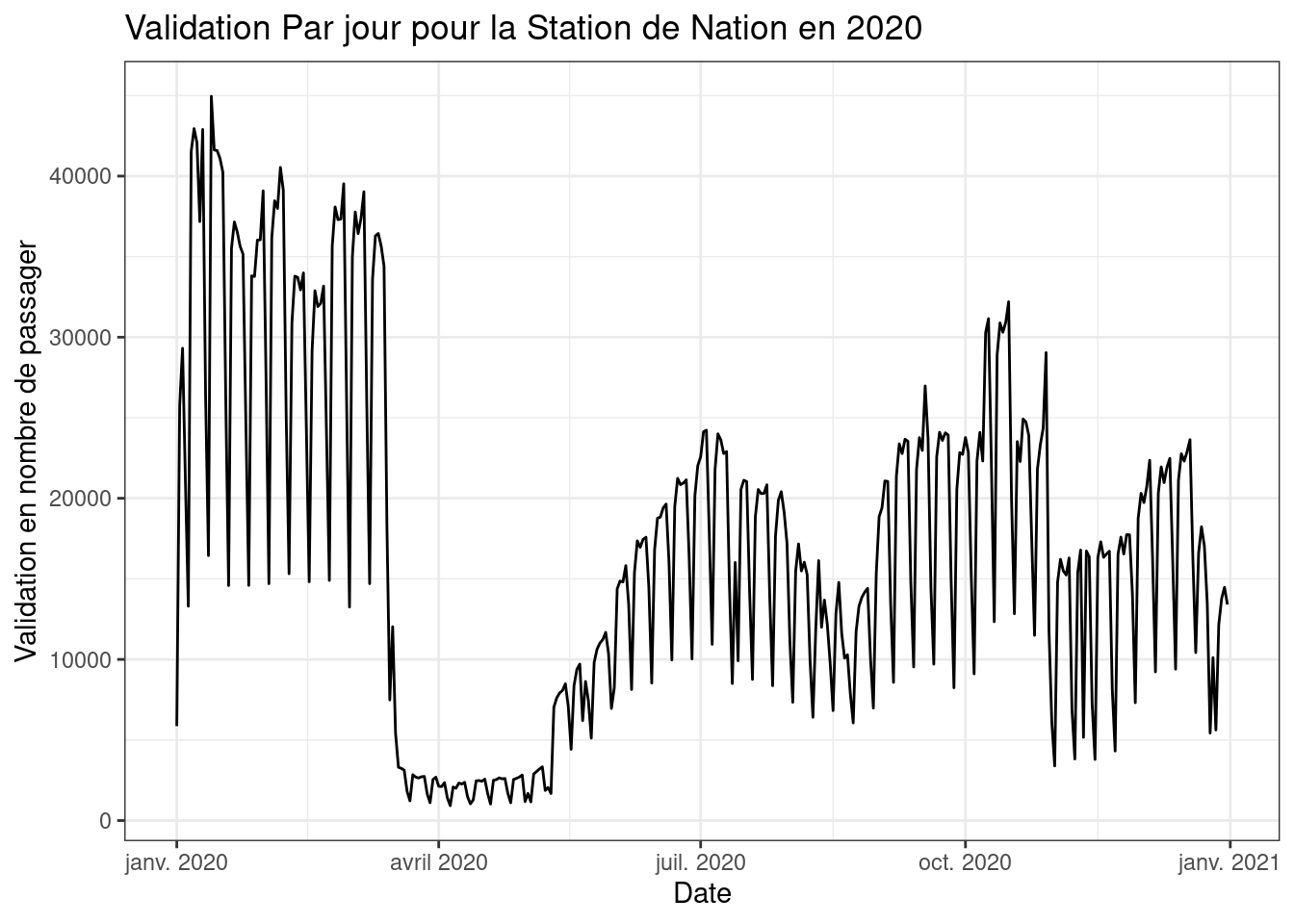
Il est possible de cumuler plusieurs graphiques en additionnant les fonctions de dessins “geom” pour synthétiser plusieurs conclusion. Par exemple le graphique suivant montre l’augmentation progressive du volume passagers suite au confinements tout en affichant les différents confinement sur 2020 et 2021.
# Visualisation de l'évolution d'une station durant la période étudier
see = data.val.cl4 |> filter(NAME == "NATION") |> filter(year > 2019)
ggplot(see) +
geom_line(aes(JOUR, NB_VALD))+
geom_smooth(aes(JOUR, NB_VALD), method= "lm")+
labs(x = 'Date' , y = 'Validation en nombre de passager', title = 'Validation Par jour pour la Station de Nation en 2020') +
theme_bw()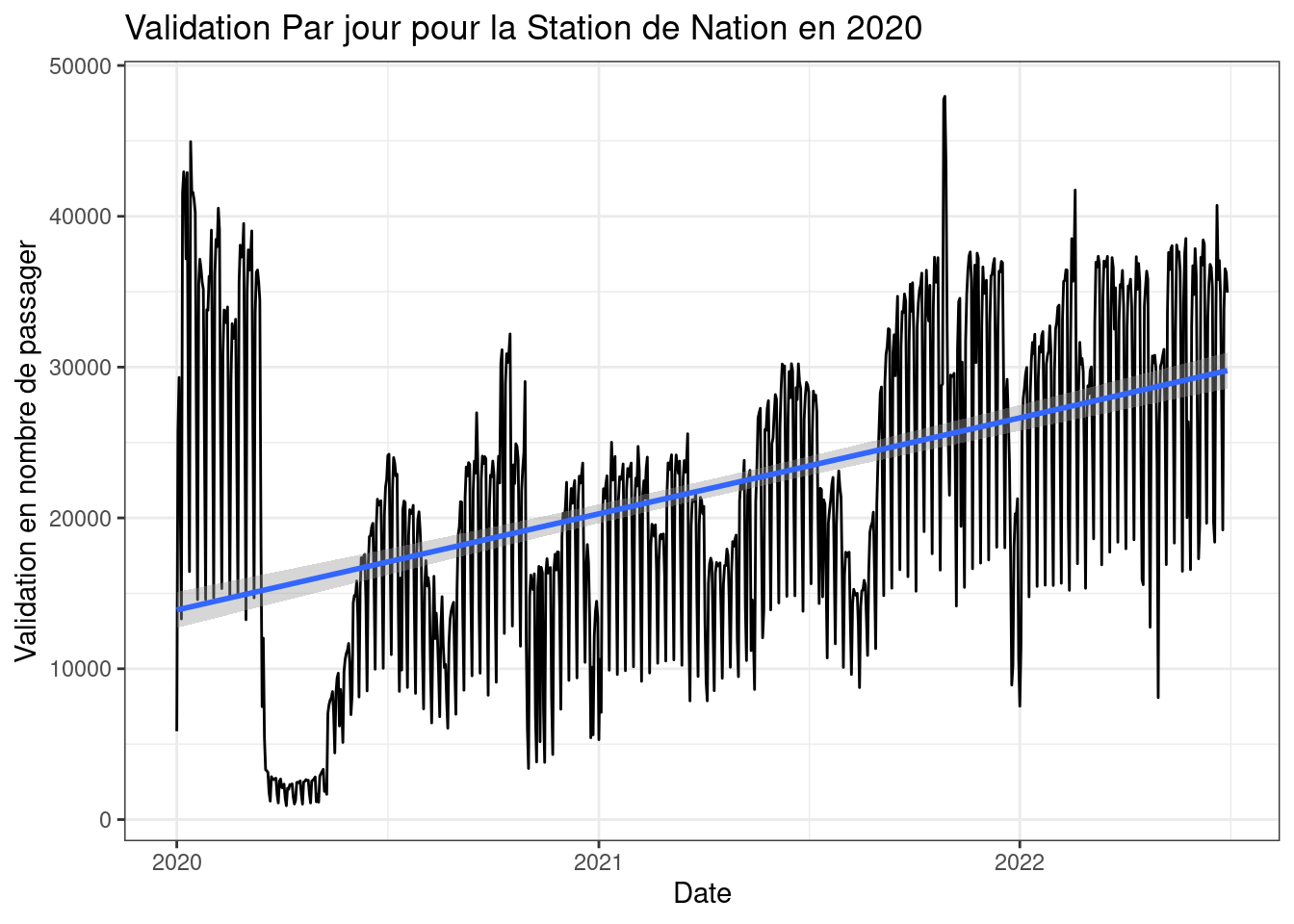
Attention pour l’usage de certaines fonctions, des paramètres peuvent biaiser le rendu. Dans le cadre du geom_smooth par exemple, le choix de la fonction doit être fait de manière pertienente et selon les données (ici la fonction “loess” peut être plus intéressante pour représenter la tendance des volumes de passagers.). Il est aussi possible d’utiliser des fonctions personalisées via des formules (ex : y ~ poly(x, 2), y ~ log(x))
Cependant, la taille du jeu de données impliquent que toutes les données ne peuvent pas toujours être afficher pour avoir un résultat observable. Ainsi le graphique suivant montre le volume de passager moyen sous jeux de données pour les 15 stations avec le plus grand volume de passagers pour ne pas avoir à afficher l’intégralité des 732 stations.
# créer de nouvelles variables
comp = data.val.cl4 |>
filter(wd %in% c(2,3,4,5,6)) |>
group_by(NAME) |>
summarise(n = mean(NB_VALD)) |>
arrange(desc(n) ) |>
mutate(type_jour = "Ouvré")
weekend = data.val.cl4 |>
filter(wd %in% c(1,7)) |>
group_by(NAME) |>
summarise(n = mean(NB_VALD)) |>
arrange(desc(n) ) |>
mutate(type_jour = "Weekend")
comp = bind_rows(comp,weekend)
biggest_station = comp |> slice(1:15) |> arrange(desc(n)) |> select(NAME)
df = comp |> filter(NAME %in% biggest_station$NAME)
ggplot(df) +
geom_col(aes(n, reorder(NAME, n, sum), fill = type_jour), position="dodge")+
labs(x = 'Volume passager moyen' , y = '', title = 'Les 15 plus grandes stations en volume passager par type de jour') +
scale_color_brewer(palette="Set2")+
theme_bw()+
theme(legend.position="bottom")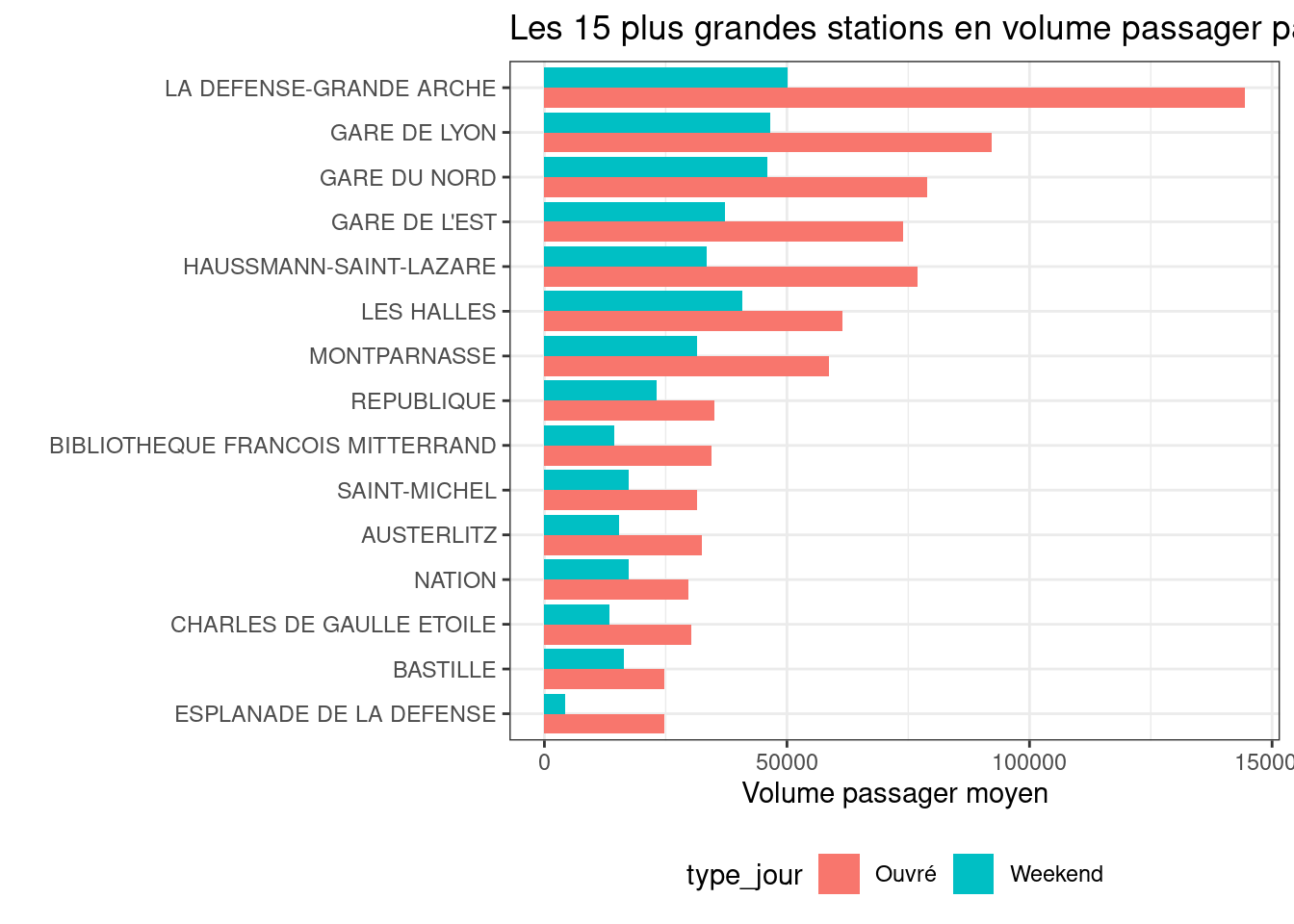
De plus, on peut aussi faire des études différenciées entre les hub des TC parisiens en utilisant des graphiques précédemment utilisé en ayant un focus sur un nombre limité de stations.
# Visualisation de l'évolution d'une station durant la période étudier
comp = data.val.cl4 |> filter(NAME %in% c("LA DEFENSE-GRANDE ARCHE","GARE DE LYON" )) |> filter(year == 2020)
ggplot(comp, aes(JOUR, NB_VALD, linetype = NAME, color=NAME)) +
geom_line()+
scale_color_brewer(palette="Set2")+
labs(x = 'Date' , y = 'Validation en nombre de passager',
title = 'Comparaison du volume passager entre Nation et Gare de Lyon en 2020') +
theme_bw()+
theme(legend.position="bottom")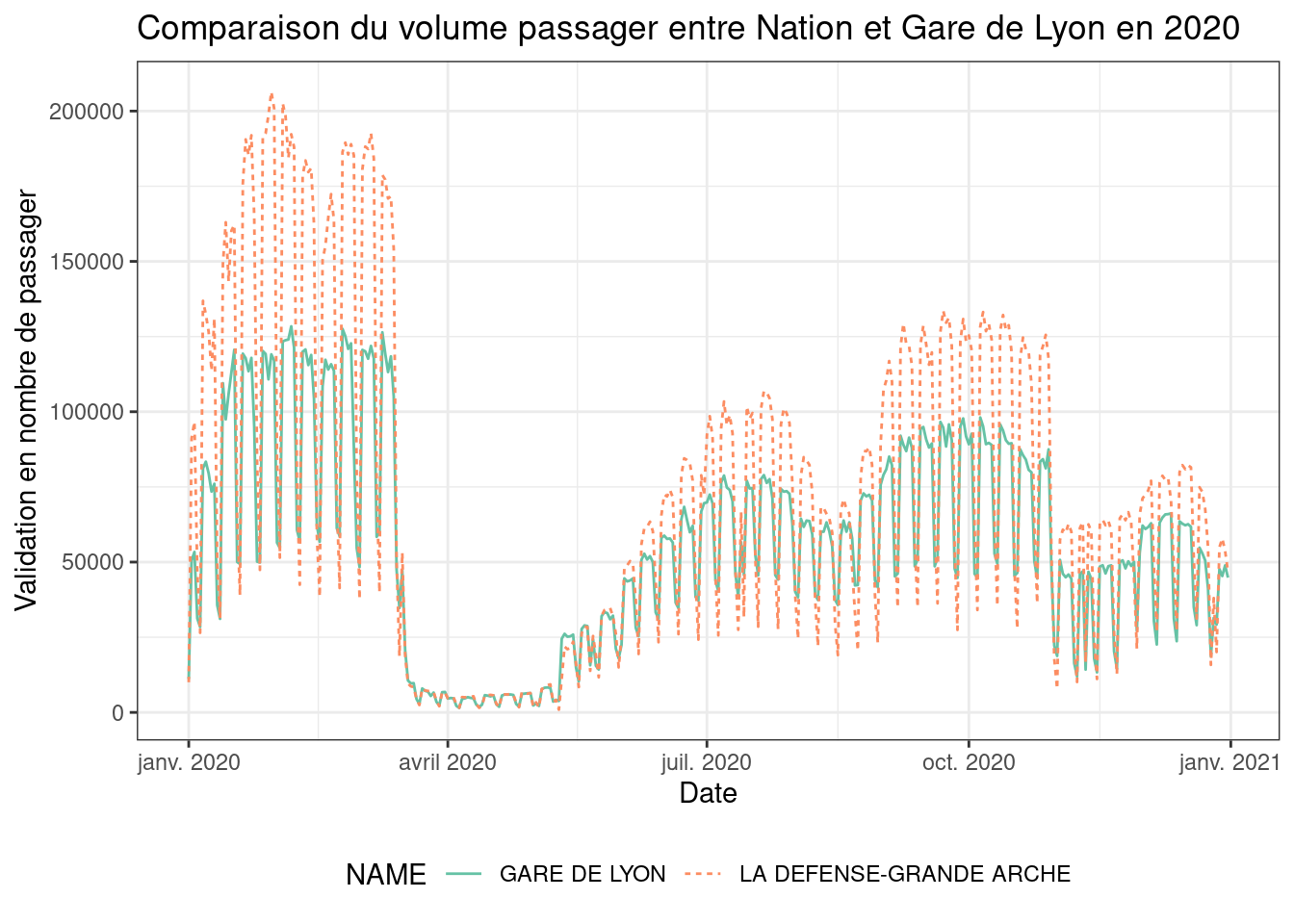
Cependant, ces visualisations ne permettent pas de tenir compte de la composante spatiale des données.
Données spatiales
Pour comprendre les dynamiques spatiales et temporelles des flux de passagers au sein de la métropole parisienne, on peut utiliser les identifiants stations pour projeter sur une carte de l’Île de France nos données. Pour se faire, il faut utiliser un réferentiel IDFM des positions GPS des stations : https://data.iledefrance-mobilites.fr/api/datasets/1.0/referentiel-arret-tc-idf/attachments/2021_idfm_referentiels_pdf/
La jointure est effectué grâce au code des stations en se limitant uniquement au réseau ferré. Les stations sont présentées sous la forme de shapefiles pour toutes les stations dont on extrait les centroids comme coordonées GPS.
A ce stade, chaque série est associée à des coordonées que l’on represente sur une carte via le package leaflet afin de proposer une carte intéractive de nos données.
# recuperation des données spatiales
url = "https://data.iledefrance-mobilites.fr/api/explore/v2.1/catalog/datasets/referentiel-arret-tc-idf/exports/csv?lang=fr&timezone=Europe%2FBerlin&use_labels=true&csv_separator=%3B"
#download.file(url,"./data-raw/referentiel-arret-tc-idf.csv")
ref_urls=read_delim("./data-raw/referentiel-arret-tc-idf.csv",delim=";")
#download.file(ref_urls |> filter(Fichier=="REF_LDA.zip") |> pull(`Lien de téléchargement`),destfile = "./data-raw/REF_LDA.zip")
#unzip("./data-raw/REF_LDA.zip",exdir = "./data-raw")
# lecture / filtrage / pré-traitement
type_arr = c("Station de métro","Station ferrée / Val")
ref.lda = read_sf("./data-raw/PL_LDA_25_01_2023.shp") |>
mutate(ID_REFA_LDA=as.character(id_refa)) |>
filter(type_arret %in% type_arr)
ref.lda.centroid = ref.lda |> st_centroid()
# carte interactive avec leaflet, carte simple suivante le type d'arret
library(leaflet)
factpal <- colorFactor("Set2", ref.lda$type_arret)
leaflet(data = ref.lda.centroid |> st_transform(4326)) %>% addTiles() %>%
addCircles( label = ~ paste(nom,", ",type_arret, "\n id: ",ID_REFA_LDA),color=~factpal(type_arret),opacity = 1,radius =~ 50)# carte avec symboles proprotionels ! a la racine carré
st.stats.sf = ref.lda.centroid |> st_transform(4326) |> left_join(st_glob_stats) |> filter(!is.na(M_VALD))
leaflet(data = st.stats.sf ) %>% addTiles() %>%
addProviderTiles(providers$CartoDB.Positron) %>%
setView(zoom = 12,lng=2.3510768,lat=48.8567879 ) |>
addCircles( label = ~ paste(nom,", ",type_arret, "\n id: ",ID_REFA_LDA),
color=~factpal(type_arret),opacity = 1,radius =~ sqrt(M_VALD*5),weight = 1,fillOpacity = 0.65)Autres données disponnibles
Le données en open data d’IdFM ne se limites pas aux données de validations journalières, vous pouvez également analyser les données de profils journaliers :
profs2018 = read_delim("./data-raw/data-rf-2018/2018_S1_PROFIL_FER.txt", delim = "\t",locale = locale(decimal_mark = ",")) |>
mutate(periode="1er Semestre 2018")
profs2021 = read_delim("./data-raw/data-rf-2021/2021_S1_PROFIL_FER.txt",delim="\t",locale = locale(decimal_mark = ","))|>
mutate(periode="1er Semestre 2021")
profs = bind_rows(profs2018,profs2021) |>
filter(TRNC_HORR_60!="ND") |>
separate(TRNC_HORR_60,c("Hdeb","Hfin"),"-") |>
mutate(H=as.numeric(gsub("H","",Hdeb)))
gg=profs |> filter(ID_REFA_LDA==71379,CAT_JOUR%in%c("JOHV","SAHV"),CODE_STIF_RES=="110")
ggplot(gg)+
geom_line(aes(x=H,y=pourc_validations,color=periode,group=periode))+
scale_x_continuous(breaks=seq(0,23,by=2),minor_breaks = seq(1,23,by=2))+
scale_color_brewer("Période :",palette = "Set2")+
labs(title="Profils de validation journaliers",
subtitle="de la station de métro Porte Maillot en 2018 et 2021, suivant le type de jours",
x="Tranche horaire",
y="Pourcentage de validations (%)")+
facet_wrap(~CAT_JOUR)+
theme_bw()+
theme(legend.position="bottom")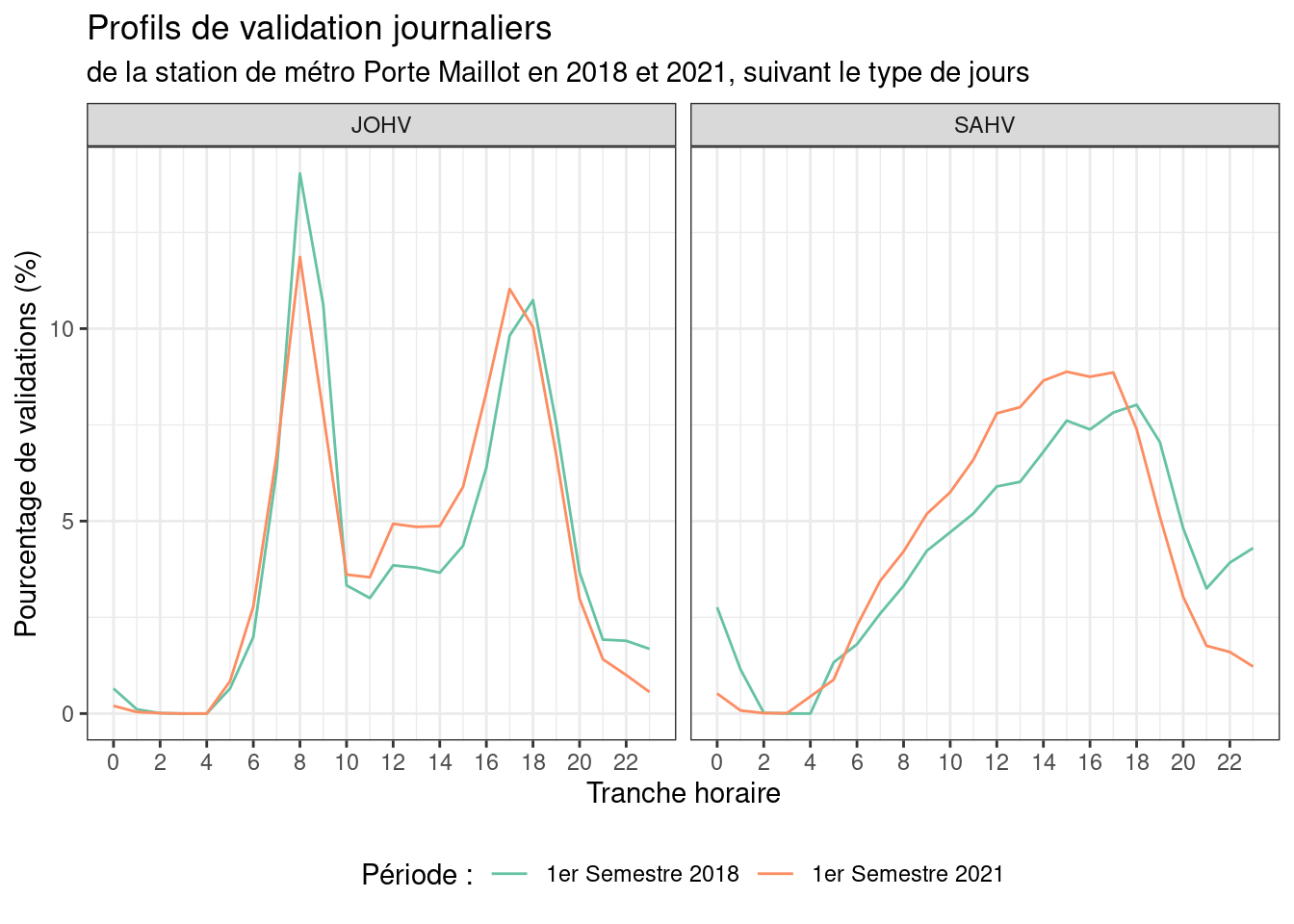
Bien d’autres données sont disponibles sur la plateforme d’IdFM. Même les données de régularités de ce pdf si vous le souhaitez (voir le script ponctualite.R). Ces données sont utilisées à titre d’exemple par les récents articles de franceinfo et du Monde
N’hésitez pas à explorer la plateforme et à poser des questions.
A vous de jouer !